Why can’t I just naively load chunks?
First, let me explain why I chose to implement this slightly complicated chunk loading system in my voxel-engine. Creating and rendering a chunk requires the following steps:
(i) [CPU] : Any meshing algorithm.
(ii) [CPU] : Create the relevant GPU buffers (which typically includes two resources, one on a default heap and one on a upload heap (unless you use rebar)).
(iii) [CPU] : Copy the CPU side data to the upload buffer.
(iv) [GPU] : Execute a copy resource command so that data from the upload buffer is copied to the default buffer.
(v) [CPU] : Check if / wait till the data is ready in the default buffer.
(vi) [CPU] : Add chunk to the render list and render.
If you naively load chunks, you are likely to run into a few problems since you can run the meshing algorithm only one chunk at a time, potentially causing the CPU to become a bottleneck if you want to create multiple chunks per frame.
If you try to load multiple chunks per frame, while new chunks are being loaded, the entire application will start to lag, becoming nearly unusable.
Multi-Threading the Chunk loading process
Inorder to create multiple chunks per frame, you can launch a thread for each chunk. By doing so, the meshing process happens on a different thread for each chunk, which significantly reduces lag and enables you to load multiple chunks per frame.
I use std::future and std::async to simplify this process. When you want to call a function on a different thread that returns a value, you can use std::future.
You can periodically check the status of the future using std::future_status to determine if the thread has finished execution and if you can retrive the actual function return value from the future.
In my code, I use std::future / std::async in the following way:
// I have a queue of std::pair<size_t, std::future<SetupChunkData>> named
// 'm_setup_chunk_futures_queue'. I populate this queue by:
void ChunkManager::create_chunks_from_setup_stack(Renderer &renderer)
{
// Note : Command list recording is not thread-safe, so before recording
// any GPU commands make sure that each thread has its own command list, or you have the proper sync primitives in place.
m_setup_chunk_futures_queue.emplace(
std::pair{renderer.m_copy_queue.m_monotonic_fence_value + 1,
std::async(&ChunkManager::internal_mt_setup_chunk, this,
std::ref(renderer), top)});
}
// Link : https://github.com/rtarun9/voxel-engine/blob/58b83510cbde664b6ec191af46eb66a083f33d6b/src/voxel.cpp#L257
// Then, I have a function that checks the status of the std::future at the front of the
// queue:
void ChunkManager::transfer_chunks_from_setup_to_loaded_state(const u64
current_copy_queue_fence_value)
{
while (!m_setup_chunk_futures_queue.empty() && ......)
{
auto &setup_chunk_data = m_setup_chunk_futures_queue.front();
// Wait for 0 seconds and check the status of future.
switch (std::future_status status = setup_chunk_data.second.wait_for(0s); status)
{
case std::future_status::timeout: {
// Chunk is not loaded, return and check for the status in the next frame.
return;
}
break;
case std::future_status::ready: {
// The future is ready, the .get() function can be used to access the function
// return value and chunk can be loaded and rendered!
SetupChunkData chunk_to_load = setup_chunk_data.second.get();
.......
}
}
}
}
// Link : https://github.com/rtarun9/voxel-engine/blob/58b83510cbde664b6ec191af46eb66a083f33d6b/src/voxel.cpp#L268
Fantastic! Now, chunks can be meshed and setup on a different thread, and now the application will not slow down so much! But wait, we have only improved the chunk loading processes on the cpu. Remember that we still have to execute the copy resource command on the GPU.
With the current multi threaded system, say you load 32 chunks a frame in a multi-threaded fashion. Now, you will need to execute 32 CopyResource commands on the GPU, and with a single queue, your draw calls and copy resource calls need to be completed together before the command queue is signalled. This means, the time to process the commands for each frame increases significantly.
Is there a alternative to this?
Using Multiple GPU Command Queues
What is a Command Queue?
In D3D12 terms, a command queue provides methods for submitting command lists, synchronizing command list execution, etc. A command queue is essentially a ’execution port’ for the GPU.
In D3D12, you have multiple types of command queues, namely:
(i) Direct (No restrictions on the commands it can execute)
(ii) Compute
(iii) Copy
Now, your draw calls execute on the Direct queue. Your GPU may have multiple dedicated queues that can execute commands in parallel. This means, you can have one queue (Direct command queue) for rendering, and one queue (Copy command queue) specifically for your CopyResource calls.
Here’s a screenshot from task manager, which shows that my GPU (Nvidia GTX 1650) has a dedicated copy queue.
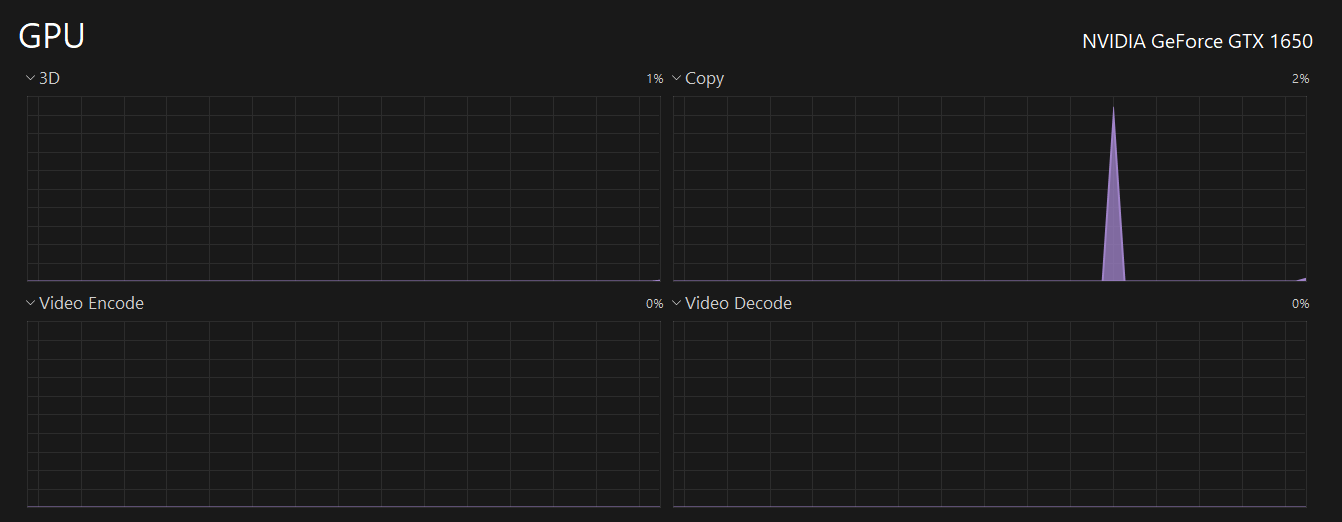
So now, the renderer can utilize a dedicated copy and direct queue in the following ways:
(i) In the multi-threaded chunk meshing function, the CopyResource command is recorded by a command list that is submitted to a copy queue.
(ii) In the main render loop, all rendering commands are submitted to the dedicated direct queue.
Synchronizing between the 2 queues
For the specific requirements of my voxel-engine, no GPU-GPU sync is required. Instead, what I do is:
(i) Use a std::pair<size_t, std::future> where the first component of the pair is the fence value that the copy queue is signaled with.
This can be used to determine if the CopyResource command for a particular chunk has completed execution.
(ii) Each frame, check the above step for a few chunks and move them onto another data structure so that they can be rendered.
The chain of functions called is as follows:
// Called from the main thread.
void ChunkManager::create_chunks_from_setup_stack(Renderer &renderer)
{
// When adding the the std::future queue, also push the copy queue fence value:
m_setup_chunk_futures_queue.emplace(
std::pair{renderer.m_copy_queue.m_monotonic_fence_value + 1,
std::async(&ChunkManager::internal_mt_setup_chunk, this,
std::ref(renderer), top)});
}
// Called from multiple worker threads
ChunkManager::SetupChunkData ChunkManager::internal_mt_setup_chunk(Renderer
&renderer, const size_t index)
{
// Meshing algorithm...
setup_chunk_data.m_chunk_index_buffer =
renderer.create_index_buffer((void *)setup_chunk_data.m_chunk_indices_data.data(),
sizeof(u16), setup_chunk_data.m_chunk_indices_data.size(),
std::wstring(L"Chunk Index buffer : ") + std::to_wstring(index));
}
// Called from multiple worker threads
// EACH of the create_X_buffer functions internally call:
Renderer::IndexBufferWithIntermediateResource Renderer::create_index_buffer
(const void *data, const size_t stride,
const size_t indices_count,
const std::wstring_view buffer_name)
{
// Required since these chain of functions are called by multiple threads at once.
std::scoped_lock<std::mutex> scoped_lock(m_resource_mutex);
auto command_allocator_list_pair = m_copy_queue.
get_command_allocator_list_pair(m_device.Get());
command_allocator_list_pair.m_command_list->CopyResource(buffer_resource.Get(),
intermediate_buffer_resource.Get());
m_copy_queue.execute_command_list(std::move(command_allocator_list_pair));
}
// Called from single worker thread
void Renderer::CopyCommandQueue::execute_command_list(CommandAllocatorListPair
&&alloc_list_pair)
{
throw_if_failed(alloc_list_pair.m_command_list->Close());
ID3D12CommandList *const command_lists_to_execute[1] =
{alloc_list_pair.m_command_list.Get()};
m_command_queue->ExecuteCommandLists(1u, command_lists_to_execute);
throw_if_failed(m_command_queue->Signal(m_fence.Get(), ++m_monotonic_fence_value));
alloc_list_pair.m_fence_value = m_monotonic_fence_value;
m_command_allocator_list_queue.push(alloc_list_pair);
}
Now that each future is paired with the fence value, on the CPU side we can check if a chunk is ready to be loaded and rendered:
void ChunkManager::transfer_chunks_from_setup_to_loaded_state(const u64 current_copy_queue_fence_value)
{
using namespace std::chrono_literals;
u64 chunks_loaded = 0u;
while (!m_setup_chunk_futures_queue.empty() && chunks_loaded < ChunkManager::NUMBER_OF_CHUNKS_TO_LOAD_PER_FRAME)
{
// Load the chunk if ready!
}
}
Using this mechanism (no GPU GPU sync), the code is heavily simplified.
A diagram to explain this logic:
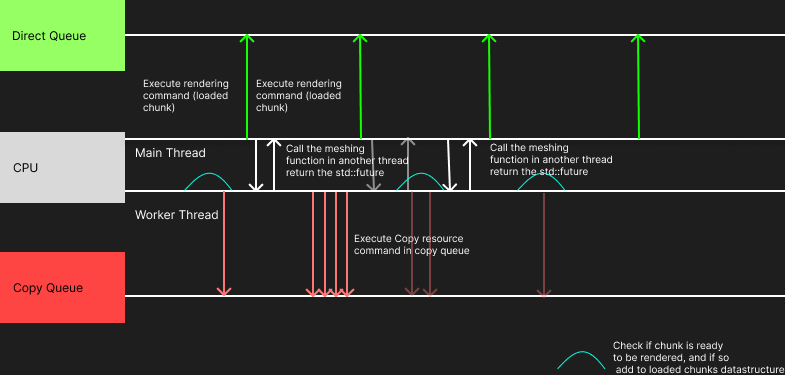
Here, we see that the direct queue doesn’t wait for the copy queue. The worker threads (there are multiple of them, but the diagram only shows one for simplicity) run the meshing algorithm, get a command list, record the CopyResource call, and submit to the copy queue for execution. The CPU takes the loaded chunks, adds them to a data structure (in my case: a hashmap), and fills the indirect command buffer with relevant info.
The Direct queue uses the indirect command buffer to perform GPU culling, where the non culled chunks are rendered.
Using a thread pool over std::async
If in your engine, you load multiple chunks each frame, you might find the application slow down a lot because of the overhead of launching / starting multiple new threads each time.
In this case, you might want to consider replacing std::async with a thread pool like BS::thread-pool. In a thread pool, threads are created at start up and the same threads are re-used. Essentially, the ‘overhead’ of launching a new thread each time is eliminated.
However, if you have X threads in your thread pool and want to launch > X threads, a few threads will stall. This is a fine tradeoff to make, as the main thread is unaffected and will NOT face any delays / lag when compared to using std::async.
Closing Thoughts
Implementing async copy is very similar to multi-threading. It does make your code more complex, but it does use your hardware more efficiently, and when your GPU has dedicated queues, why not use it?
Thank you so much for your time! Feel free to leave comments if you felt something was lacking/incorrect or your opinions on my post! If you would like to reach out to me, head over to the Home page to find some contact links there.
More Detailed Resources
If you want to go deeper into async copy / multi-threading, here are some resources I have found to be very helpful:
CPP Reference’s std::future section
D3D12’s Design Philosophy of Command Queues and Command Lists